
2013 RESULTS
Task 2
Adapt for isotropic dislocation kernels
In order to allow larger Dislocation Dynamics simulations we focused on developing an efficient formulation of the isotropic elastic interaction forces between dislocations. We considered a tensorial interpolation scheme using Chebyshev polynomials and developed an efficient summation scheme suitable for fast multipole summation. The new algorithm based on this formulation is currently being implemented in the DD-code OptiDis, where the fast multipole summation is handled by ScalFMM library.Task 3 - Fast Linear solver
- Stanford Group Development of a series of fast direct solvers. In particular we now have a direct solver that uses various low-rank compression methods (adaptive cross-approximation, pseudo-skeleton, rank revealing LU) and fast solvers (based on Sherman-Morrison, recursive block LU factorization). We created a new type of solver called extended sparsification in which a dense linear system of size N is replaced by a sparse linear system of size ~ 3N, which can be solved in O(N) floating point operations (fill-in is avoided during that process, resulting in O(N) flops only).
- Berkeley Group
- PDSLin Solver Development: In the past six months, we continued to investigate some combinatorial algorithms to enhance PDSLin's performance, and presented the new results at the IPDPS 2013 conference. We are helping the ComPASS SciDAC project to incorporate PDSLin into the Omega3P eigensolver code.
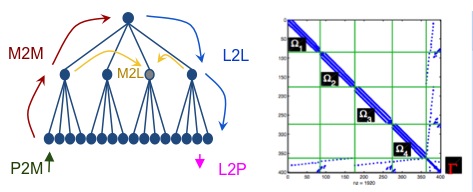
- Low Rank Factorizations and HSS Methods: In the past six months, we have improved our parallel algorithms for the key HSS operations that are used for solving large linear systems. These are the parallel rank-revealing QR factorization, the HSS constructions with hierarchical compression, the ULV HSS factorization, and the HSS solutions. Our paper is accepted for publication in the SIAM J. Sci. Comput. We also improved the parallel geometric multifrontal solver using the parallel HSS low-rank structures for the separator submatrices. We demonstrated that the largest problem the new code could solve is the 3D Helmholtz equations of size 600^3, using 16,000+ cores. We finished the detailed algorithm paper and submitted it to the ACM. Trans. Math. Software.
- Sparse Symmetric Solver Development: One of the crucial steps in a sparse symmetric solver is permuting (or ordering) the rows and columns of the matrix so that a certain metric is optimized. Examples of metrics are the number of fill entries introduced in sparse symmetric factorization and the number of floating-point operations to be performed during factorization. We recently demonstrated that an optimal ordering that minimizes the number of fill entries in the triangular factor does not necessarily minimize the number of floating-point operations performed, and vice versa. This result has prompted us to re-examine the minimum local fill (MLF) and minimum degree (MD) heuristics -- the former attempts to minimize the fill introduced at each step of the factorization while the latter reduces the number of operations. The MLF heuristic has long been considered to be inferior when compared with the MD heuristic because of the high cost of running the MLF heuristic. However, in the past six months, we have produced an implementation of the MLF heuristic that compares favorably with the MD heuristic in terms of run-time and yet the quality of the MLF orderings can be superior than that of the MD orderings. We have also begun the investigation of the fan-both approach for implementing parallel sparse Choleksy factorization, which can result in less communication than the fan-in and fan-out approaches.
- Inria group - For the solution of large sparse linear systems, we have consolidated and designed new functionalities in the MaPhyS package in order to enlarge and enrich the planned comparison between our solver and PDSLin developed at LBNL. With the upgraded version of our package, we now succeed to solve some of the difficult linear systems provided by Berkeley in the jointly defined benchmark suite. We are now in situation to investigate the relative performance (memory, elapsed time) of the two solvers. To this end, our code was ported on NERSC computer while PDSLin was ported to Inria's platform. These two platforms will thus be used for the comparative study.
Task 4 - Fast Multipole Method
Last year we have worked primarily on developing an efficient fast multipole method for dislocation dynamics applications. Some of the accomplishments for this year include:
- Implementation of the FMM of multicore machines using StarPU. A new parallel scheduler was developed for this purpose. We implemented a state-of-the-art OpenMP version of the code for benchmarking purposes. It was found that StarPU significantly outperforms OpenMP.
Figures show the traces of an execution of the FMM algorithm with our priority scheduler for the cube (volume) and ellipsoid (surface) with 20 million particles on a 4 deca-core Intel Xeon E7-4870 machine.

- Implementation of the FMM of heterogeneous machines (CPU+GPU) using StarPU. The FMM was also used to demonstrate the flexibility of StarPU for handling different types of processors. In particular we demonstrated in that application that StarPU can automatically select the appropriate version of a computational kernel (CPU or GPU version) and run it on the appropriate processor in order to minimize the overall runtime. Significant speed-up were obtained on heterogeneous platforms compared to multicore only processors.
These contributions will be presented in minnisymposia at the SIAM conference on Comutational Sciences and Engineering (SCE13) in Boston. More details and results can be found in report RR-8277 (pdf), our paper is accepted for publication in the SIAM Journal on Scientific Computing
 Menu
Menu See also
See also Contact
Contact